快速开始
安装
pip install pyspider
命令行运行 pyspider
浏览器运行脚本编辑界面WebUI http://localhost:5000/
如果你使用的是ubuntu系统,尝试:
apt-get install python python-dev python-distribute python-pip \
libcurl4-openssl-dev libxml2-dev libxslt1-dev python-lxml \
libssl-dev zlib1g-dev
先去安装二进制的包
如果需要请安装PhantomJS http://phantomjs.org/build.html
应该注意PhantomJS只有把启动路径添加到系统环境中才能使用。
注意:pyspider命令是默认启动所all模型,该模型是使用线程和子进程的。有关生产环境的,请转到链接Deployment阅读
警告:脚本编辑界面WebUI,是对外开放的。这会对你的电脑造成不必要的风险,请在内网下使用它。
编写第一个脚本
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
def on_start(self)是脚本的入口。当你点击表盘上的run按钮的时候,将会运行它。self.crawl(url, callback=self.index_page)*这是一个最重要的API方法。它将会添加新的任务到采集队列。通过self.crawl的参数,指定更多的选项。def index_page(self, response)会获得一个所有 Response* 对象.response.doc*是一个pyquery对象(有jQuery-like API去选择提取元素的信息)。def detail_page(self, response)返回一个字段对象作为结果。这个结果默认会被resultdb捕捉。你也可以重写on_result(self, result)方法,去管理采集的结果。
更多的内容你需要知道的
@every(minutes=24*60, seconds=0)*是一个助手去告诉调度器on_start方法每天都要运行。@config(age=10 * 24 * 60 * 60)*指定了self.crawl默认的age参数。页面类型是index_page(当callback=self.index_page的时候) age参数可以通过self.crawl(url, age=10*24*60*60)(优先级高一定)或者crawl_config(优先级底一点)指定。age=10 * 24 * 60 * 60*这个参数是告诉调度器抛弃这个请求,如果这个请求在十天之内爬过。pyspider默认是不会采集相同的url,即使你修改代码。刚开始第一次运行爬虫同时维护代码是比较常见的。第二次运行也不会重新爬取。(阅读itag去解决问题)@config(priority=2)*标记了detail pages应该先采集。
你可以调试你的脚本一步一步的点击run按钮。转到follows仪表盘,点击play按钮,去继续。
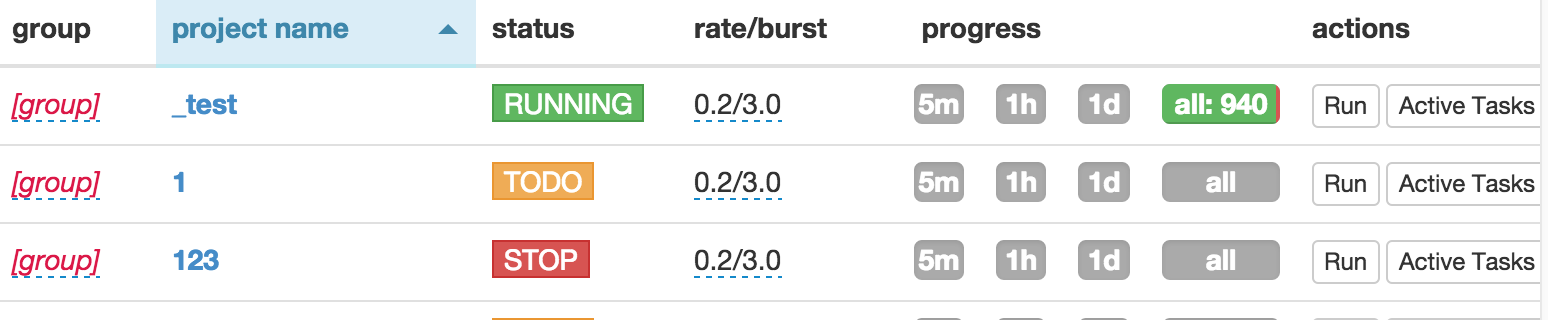
开始运行
- 保存你的爬虫
- 返回脚本编辑界面首页,找到你的项目
- 改变下状态到
DEBUG或者RUNNING - 点击
run按钮
书籍推荐