爬虫学习使用指南
Auth: 王海飞
Data:2018-06-20
Email:779598160@qq.com
github:https://github.com/coco369/knowledge
1. 使用selenium,模拟登陆知乎
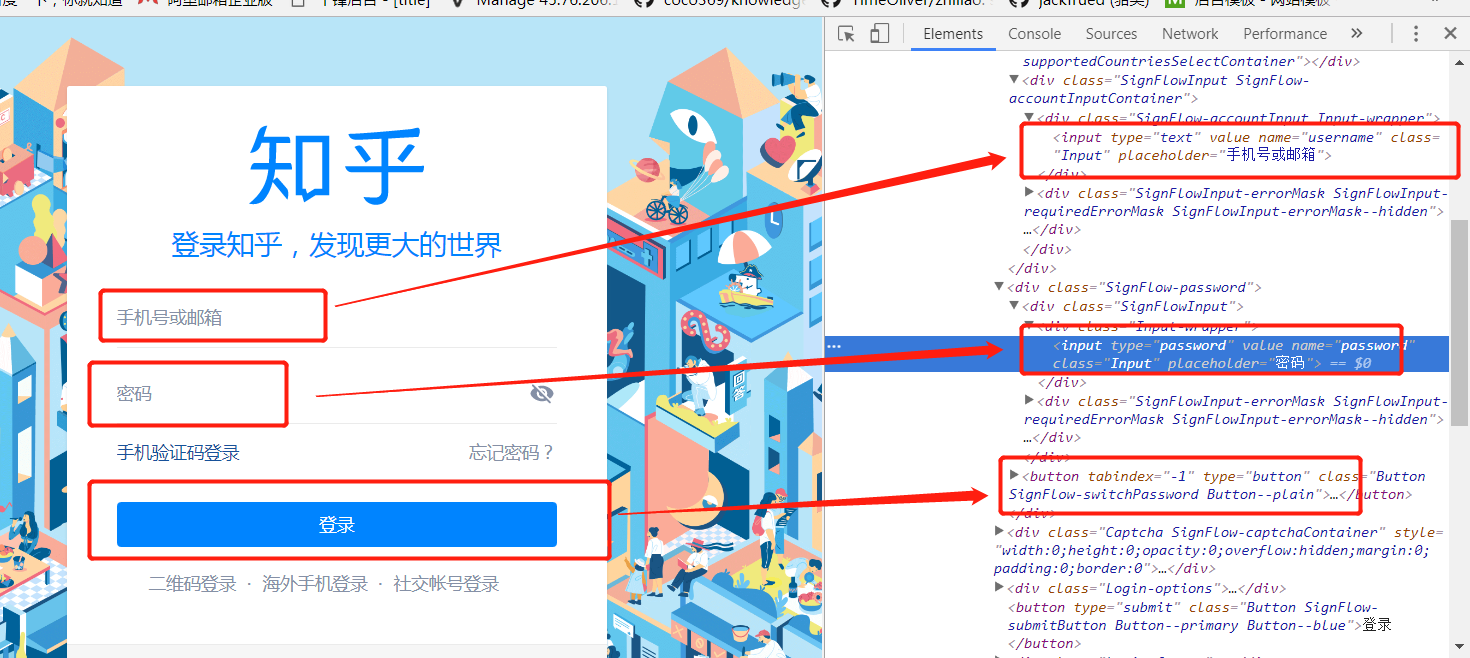
使用selenium去模拟浏览器的行为去登陆知乎,需要清楚登陆页面中的输入用户名和密码,还有登陆按钮的样式,这样selenium才能通过样式id或者class去获取到该按钮,进行相关的填入用户信息和提交的操作
from selenium import webdriver
import time
# 创建浏览器对象
chromedriver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver'
browser=webdriver.Chrome(chromedriver)
# 请求加载登录链接
browser.get('https://www.zhihu.com/signin')
time.sleep(3)
# 输入账号
browser.find_element_by_css_selector("input[name='username']").send_keys('17078075655')
# 输入密码
browser.find_element_by_css_selector("input[name='password']").send_keys('19910825580lb')
# 模拟点击登录
browser.find_element_by_css_selector(".SignFlow-submitButton").click()
time.sleep(3)
# 截图
browser.save_screenshot("zhihu.png")
browser.quit()
小结:输入文字用send_keys()方法,清空文字用clear()方法,另外还有按钮点击,用click()方法
2. 使用selenium去爬取豆瓣电影的信息
简单的:
from bs4 import BeautifulSoup
from selenium import webdriver
def main():
chromedriver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver'
driver = webdriver.Chrome(chromedriver)
driver.get('https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0')
soup = BeautifulSoup(driver.page_source, 'lxml')
for img_tag in soup.body.select('img[src]'):
print(img_tag.attrs.get('src'))
print(img_tag.attrs.get('alt'))
if __name__ == '__main__':
main()
升级:
模拟打开浏览器的页面,并且滑动滚动条到底部,进行点击加载更多电影的按钮,循环多次去加载,最后获取网页的源码信息
import time
from selenium import webdriver
def more_movie(browser):
try:
time.sleep(3)
# 滚动条到底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 模拟点击豆瓣加载电影的案例
browser.find_element_by_xpath('//*[@id="content"]/div/div[1]/div/div[4]/a').click()
time.sleep(3)
except:
print('到底了')
def scroll_douban():
chromedriver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver'
browser = webdriver.Chrome(chromedriver)
browser.get('https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0')
# 滚动条到底部
# browser.execute_script('document.documentElement.scrollTop=10000')
# 滚动条到顶部
# browser.execute_script('document.documentElement.scrollTop=0')
# 循环3次去加载电影的数据
for i in range(3):
more_movie(browser)
# 回滚到顶部
browser.execute_script("window.scrollTo(0,0)")
# 打印网页的源码
print(browser.page_source)
# 关闭浏览器的窗口
browser.close()
if __name__ == '__main__':
scroll_douban()
书籍推荐